Pipeline code walk through – Introduction to Pipelines and Kubeflow-1
Workbench needs to be created to run the pipeline code. Follow the steps followed in Chapter 4, Vertex AI Workbench and custom model training under the section Vertex AI Workbench creation for creation of the workbench (choose Python3 machine):
Step 1: Creating Python notebook file
Once the workbench is created, open the Jupyterlab and follow the steps mentioned in Figure 6.8 to create Python notebook file:
Figure 6.8: New launcher window
- Click New launcher.
- Double click on the Python 3 notebook file to create one.
Step 2 onwards, run the codes given in separate cells.
Step 2: Package installation
Run the following commands to install the Kubeflow, google cloud pipeline and google cloud aiplatform package. (It will take few minutes to install the packages):
USER_FLAG = “–user”
!pip3 install {USER_FLAG} google-cloud-aiplatform==1.18.0 –upgrade
!pip3 install {USER_FLAG} kfp==1.8.10 google-cloud-pipeline-components==1.0
Step 3: Kernel restart
Type the following commands in the next cell, to restart the kernel. (Users can restart kernel from the GUI as well):
import os
if not os.getenv(“IS_TESTING”):
import IPython
app = IPython.Application.instance()
app.kernel.do_shutdown(True)
Step 4: Importing packages
Run the following mentioned line of codes in a new cell to import the required packages:
import kfp
from kfp.v2 import compiler, dsl
from kfp.v2.dsl import component, pipeline, Artifact, ClassificationMetrics, Input, Output, Model, Metrics
from typing import NamedTuple
from google_cloud_pipeline_components import aiplatform as gcc_aip
from google.cloud import aiplatform
Using the vertex AI pipeline, we are creating a dataset for the AutoML image from the data available in the cloud storage, training the AutoML image classification model, and evaluating the model to the thresholds. If the model performance is above the threshold, then the endpoint will be created and trained model will be deployed to the endpoint. The following figure has the flowchart of the steps carried out in the pipeline (different components of the pipeline). Except the model evaluation component, all other components are available in the google_cloud_pipeline_components package:
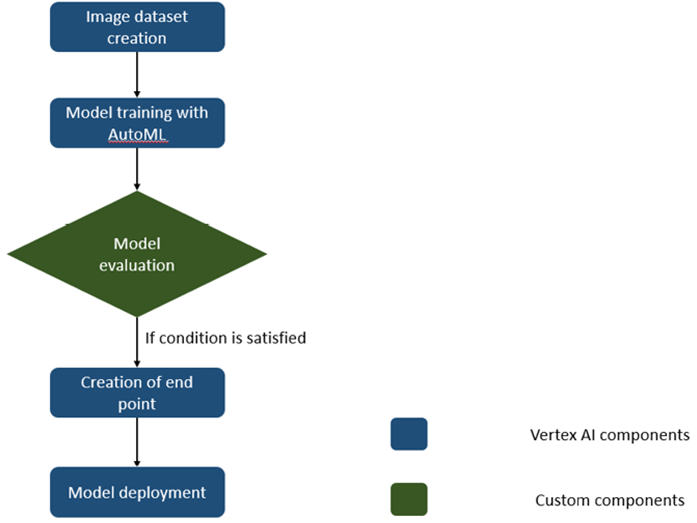
Figure 6.9: Components of pipeline
Step 4: Bucket for storing artifacts of the pipeline
Run the following mentioned line of codes to set the location to store the artifacts. Bucket will be created during the pipeline run:
PROJECT_ID = “vertex-ai-gcp-1”
bucket_name_arti=”gs://” + PROJECT_ID + “-pipeline-automl-artifacts”
PATH=%env PATH
%env PATH={PATH}:/home/jupyter/.local/bin
REGION=”us-central1”
pipeline_folder = f”{bucket_name_arti}/pipeline_automl/”
print(pipeline_folder)
Step 5: Model evaluation component of the pipeline
Run the following mentioned codes to define the custom component for model evaluation and threshold comparison which will be included in the pipeline. Important points about the following code are:
• Decorator component is used to define this function as a component of the pipeline.
• Input for the component will be the trained model (and the artifacts) which will be collected from Input[Artifacts].
• Function fetch_eval_info will fetch the evaluation data from the trained model, evaluation data will be parsed and passed to the metrics_log_check function to check if the model performance is above the threshold and return the value to be true (if the model performance is better than the threshold) or false (if other wise):
@component(base_image=”gcr.io/deeplearning-platform-release/tf2-cpu.2-5:latest”,output_component_file=”model_eval_component.yaml”,
packages_to_install=[“google-cloud-aiplatform”])
def image_classification_model_eval_metrics(
project: str,
location: str,
api_endpoint: str,
thresholds_dict_str: str,
model: Input[Artifact],
metrics: Output[Metrics],
metrics_classification: Output[ClassificationMetrics],
) -> NamedTuple(“Outputs”, [(“dep_decision”, str)]):
import json
import logging
from google.cloud import aiplatform as aip
fetch_eval_info function fetches the evaluation
information from the trained model.
def fetch_eval_info(client_name, model_name):
Refer the repository for code block of the function
return (model_eval.name,metrics_list_value,metrics_list_string)
def metrics_log_check(metrics_list_value, metrics_classification,thresholds_dict_str):
Refer the repository for code block of the function
return True
logging.getLogger().setLevel(logging.INFO)
aip.init(project=project)
extract the model resource name from the input Model Artifact
model_resource_path = model.metadata[“resourceName”]
logging.info(“model path: %s”, model_resource_path)
client_options = {“api_endpoint”: api_endpoint}
Initialize client that will be used to create and send requests.
client = aip.gapic.ModelServiceClient(client_options=client_options)
To fetch the evaluation information for the specific models
eval_name, metrics_list_value, metrics_str_list = fetch_eval_info(client, model_resource_path)
logging.info(“got evaluation name: %s”, eval_name)
logging.info(“got metrics list: %s”, metrics_list_value)
deploy = metrics_log_check(metrics_list_value, metrics_classification,thresholds_dict_str)
if deploy: _decision = “true”
else: _decision = “false”
logging.info(“deployment decision is %s”, dep_decision)
return (dep_decision,)
Leave a Reply